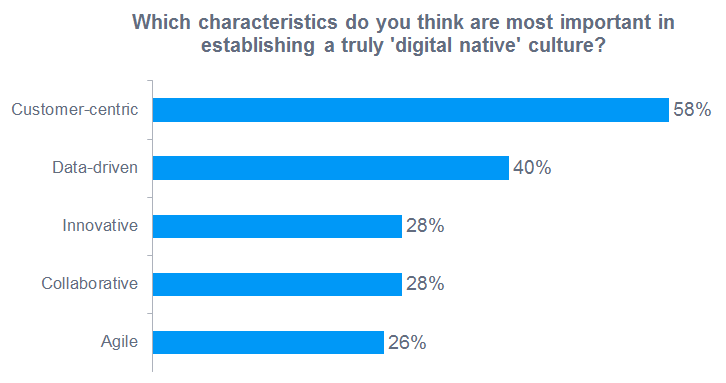
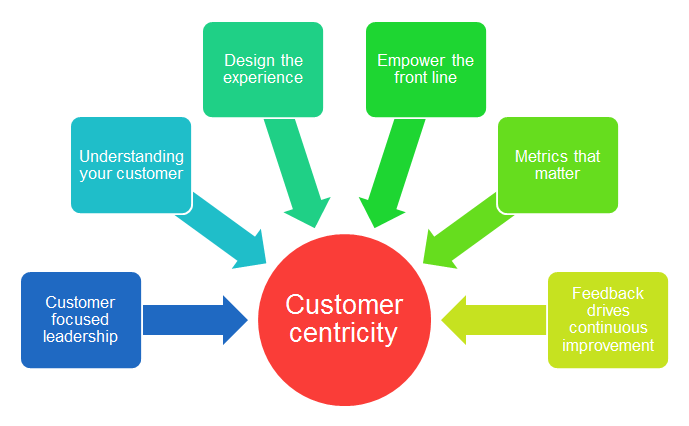
|
| Customer Analytics Flow |
1) Customer Satisfaction Analysis (Phân tích sự hài lòng của khách hàng)
Những khách hàng hài lòng với sản phẩm hoặc dịch vụ của bạn có nhiều khả năng mua lại từ bạn. Phân tích sự hài lòng của khách hàng là quá trình đánh giá xem khách hàng của bạn có nhận được những gì họ muốn và mong đợi từ doanh nghiệp, sản phẩm hoặc dịch vụ của bạn hay không - nói tóm lại là họ hài lòng hay không hài lòng. Cách phổ biến nhất để đánh giá sự hài lòng của khách hàng là kết hợp các khảo sát định lượng và định tính.
Mẹo: Thay vì chi nhiều tiền cho các cuộc khảo sát, tại sao không khuyến khích khách hàng của bạn tương tác với bạn thông qua trang Facebook, YouTube, Tiktok hoặc Twitter.
2) Customer Lifetime Value Analytics (Phân tích giá trị trọn đời của khách hàng)
Nếu bạn có thể quy một giá trị trọn đời cho mỗi khách hàng, bạn có thể thấy ngay những giá trị nào là quan trọng nhất và do đó quan trọng nhất đối với bạn. Phân tích giá trị trọn đời của khách hàng là quá trình phân tích giá trị của khách hàng đối với doanh nghiệp trong toàn bộ thời gian của mối quan hệ. Thay vì nhìn vào lợi nhuận giao dịch, bạn nhìn vào thời gian khách hàng có khả năng ở lại khách hàng, tần suất họ có thể mua trong khoảng thời gian đó và do đó họ có giá trị như thế nào trong khung thời gian đó. Điều này cho phép bạn tập trung chú ý tiếp thị vào các khách hàng có giá trị nhất. Hoàn thành tốt, phân tích này cũng có khả năng xác định các cách để tăng thời gian của mối quan hệ và giá trị của khách hàng.
Mẹo: Thách thức lớn nhất với giá trị trọn đời là tìm ra công thức phù hợp cho doanh nghiệp của bạn. Một chuyên gia KPI có thể giúp với điều này.
3) Customer Segmentation Analytics (Phân tích phân khúc khách hàng)
Phân tích phân khúc khách hàng là quá trình tìm kiếm các nhóm hoặc phân khúc trong thị trường tổng thể. Có thể đánh giá khách hàng của bạn và chia họ thành nhiều phân khúc khác nhau có thể mua nhiều sản phẩm hơn một sản phẩm khác hoặc mua thường xuyên hơn cho phép bạn điều chỉnh các nỗ lực tiếp thị và truyền thông của mình. Internet là một nguồn dữ liệu khách hàng hữu ích, giúp các công ty xác định các phân khúc rõ ràng - khai thác dữ liệu và phân tích văn bản là những công cụ hữu ích cho việc này.
Mẹo: Có thể chia các segment khách hàng gần với mô hình khách hàng lý tưởng bạn muốn hướng tới, sau đó A/B Testing để tính ROI và CLV
4) Sales Channel Analytics / Touchpoint Analytics (Phân tích kênh bán hàng và điểm chạm)
Trừ khi bạn biết cách bán hàng của bạn được thực hiện và kênh nào có lợi nhất thì bạn có thể lãng phí thời gian và tiền bạc cho các kênh bán hàng mà don lồng làm việc. Phân tích kênh bán hàng xem xét tất cả các cách khác nhau mà bạn phân phối sản phẩm cho thị trường của mình để xem kênh nào hiệu quả nhất, cho phép bạn sử dụng tốt nhất các tài nguyên của mình. Để phân tích này, bạn cần xác định tất cả các kênh bán hàng mà bạn hiện đang sử dụng hoặc có thể sử dụng, sau đó quy từng doanh số cho một kênh và trừ chi phí bán hàng có liên quan cho mỗi kênh.
Mẹo: Hãy nhớ rằng bạn không phải luôn luôn biết khách hàng có tiếp xúc với một kênh bán hàng khác trước khi mua hay không. Nói cách khác, một khách hàng có thể đã nhìn thấy sản phẩm của bạn trong một cửa hàng nhưng thích mua trực tuyến hơn.
5) Web analytics (Phân tích trang web)
Bán hàng trực tuyến chỉ trong mỗi ngành công nghiệp đang tăng lên. Phân tích trang web là quá trình phân tích hành vi trực tuyến để tối ưu hóa việc sử dụng trang web và tăng mức độ tương tác và bán hàng. Có hai loại phân tích trang web: ngoài trang web và tại chỗ. Phân tích trang web ngoài trang web rất hữu ích để đánh giá thị trường và cơ hội trong khi tại chỗ rất hữu ích để đo lường kết quả thương mại. Có nhiều công cụ phân tích trang web và nhà cung cấp dịch vụ có sẵn, chẳng hạn như Google Analytics.
Mẹo: Giá trị thực của phân tích trang web xuất hiện nếu bạn tiếp tục làm điều đó và có thể thấy hiệu suất trực tuyến của bạn thay đổi theo thời gian (số lượng user session, thời gian tương tác, tỉ lệ bounce rate)
6) Social Media Analytics (Phân tích phương tiện truyền thông xã hội)
Nếu bạn không biết những gì mọi người đang nói về công ty hoặc sản phẩm của bạn, bạn có thể giải quyết mọi vấn đề phát sinh. Phân tích phương tiện truyền thông xã hội là quá trình thu thập và phân tích dữ liệu từ phương tiện truyền thông xã hội để xem mọi người đang nói gì về sản phẩm, dịch vụ, thương hiệu hoặc công ty của bạn. Trong phân tích phương tiện truyền thông xã hội, dữ liệu văn bản từ các bài đăng và blog trên phương tiện truyền thông xã hội được thu thập và khai thác cho những hiểu biết có liên quan về mặt thương mại bằng cách sử dụng phân tích văn bản và phân tích tình cảm.
Mẹo: Sức mạnh thực sự của phân tích truyền thông xã hội là bản chất tức thời, tức thời của nó. Nếu bạn có thể phát hiện ra những khách hàng không hài lòng một cách nhanh chóng thì bạn có cơ hội để xoay chuyển tình huống đó và tạo ra một khách hàng trung thành.
7) Customer Engagement Analytics (Phân tích sự tham gia của khách hàng)
Các doanh nghiệp nổi tiếng là kém trong việc thu hút khách hàng, nhưng nó có tác động trực tiếp đến lợi nhuận của công ty. Phân tích sự tham gia của khách hàng là một lĩnh vực phát triển nhanh chóng, nơi các doanh nghiệp đang cố gắng lập bản đồ toàn bộ hành trình tương tác của khách hàng trực tuyến và ngoại tuyến. Về cơ bản, đó là quá trình đánh giá mức độ (hoặc nói cách khác) bạn thu hút khách hàng của bạn với các sản phẩm, dịch vụ hoặc thương hiệu của bạn thông qua các tương tác khác nhau này. Các cách đo lường sự tham gia của khách hàng bao gồm khảo sát và phân tích phương tiện truyền thông xã hội.
Mẹo: Bạn có thể làm hài lòng tất cả mọi người mọi lúc nhưng phân tích mức độ tương tác của khách hàng có thể giúp xác định các khía cạnh nào của giá trị sản phẩm hoặc dịch vụ của khách hàng để bạn có thể liên tục cải thiện dịch vụ của mình.
8) Customer Churn Analytics (Phân tích tỉ lệ khách rời bỏ sử dụng dịch vụ)
Giữ khách hàng hiện tại của bạn luôn dễ dàng và rẻ hơn nhiều so với cố gắng tìm kiếm khách hàng mới. Phân tích khách hàng là quá trình đánh giá số lượng khách hàng bạn mất trong suốt một năm. Nó cũng cho phép bạn dự đoán khách hàng trong tương lai và có hành động phản ứng trước khi bạn mất những khách hàng đó. Khách hàng có thể được đánh giá bằng cách sử dụng KPI như tỷ lệ giữ chân khách hàng và tỷ lệ doanh thu của khách hàng.
Mẹo: Luôn quan tâm dữ liệu sau hành động mua hàng (Post-purchased Data Points), sự hài lòng về trải nghiệm mua hàng là chìa khóa để giảm khách rời bỏ (Customer Churn)
9) Customer Acquisition Analytics (Phân tích khả năng thu hút khách hàng mới)
Nếu bạn không có đủ khách hàng, doanh nghiệp của bạn sẽ thất bại và điều tương tự cũng xảy ra nếu bạn chi quá nhiều tiền để có được những khách hàng đó. Phân tích thu hút khách hàng tìm cách thiết lập mức độ hiệu quả của bạn trong việc có được khách hàng mới, bao gồm cả hiệu quả của bạn trong việc chèn ép khách hàng từ đối thủ cạnh tranh. Có một số số liệu có thể giúp thiết lập việc thu hút khách hàng, chẳng hạn như chi phí cho mỗi khách hàng tiềm năng và tỷ lệ chuyển đổi khách hàng.
Mẹo: Khi tính chi phí cho mỗi khách hàng tiềm năng và chi phí cho mỗi khách hàng tiềm năng đủ điều kiện, hãy tính riêng chúng cho từng sáng kiến tiếp thị (marketing plan) hoặc chiến dịch bạn thực hiện. Điều này sẽ cho bạn một bức tranh rõ ràng hơn nhiều về những gì đang hoạt động và những gì không.
Các phân tích khách hàng được nêu ở đây đi đôi với các công nghệ Marketing. Nền tảng dữ liệu khách hàng (Customer Data Platform - CDP) có thể giúp bạn làm những công việc phân tích trên nhẹ nhàng hơn:
Bài viết về CDP https://knowledge.leocdp.net/2020/10/gioi-thieu-ve-customer-data-platform.html