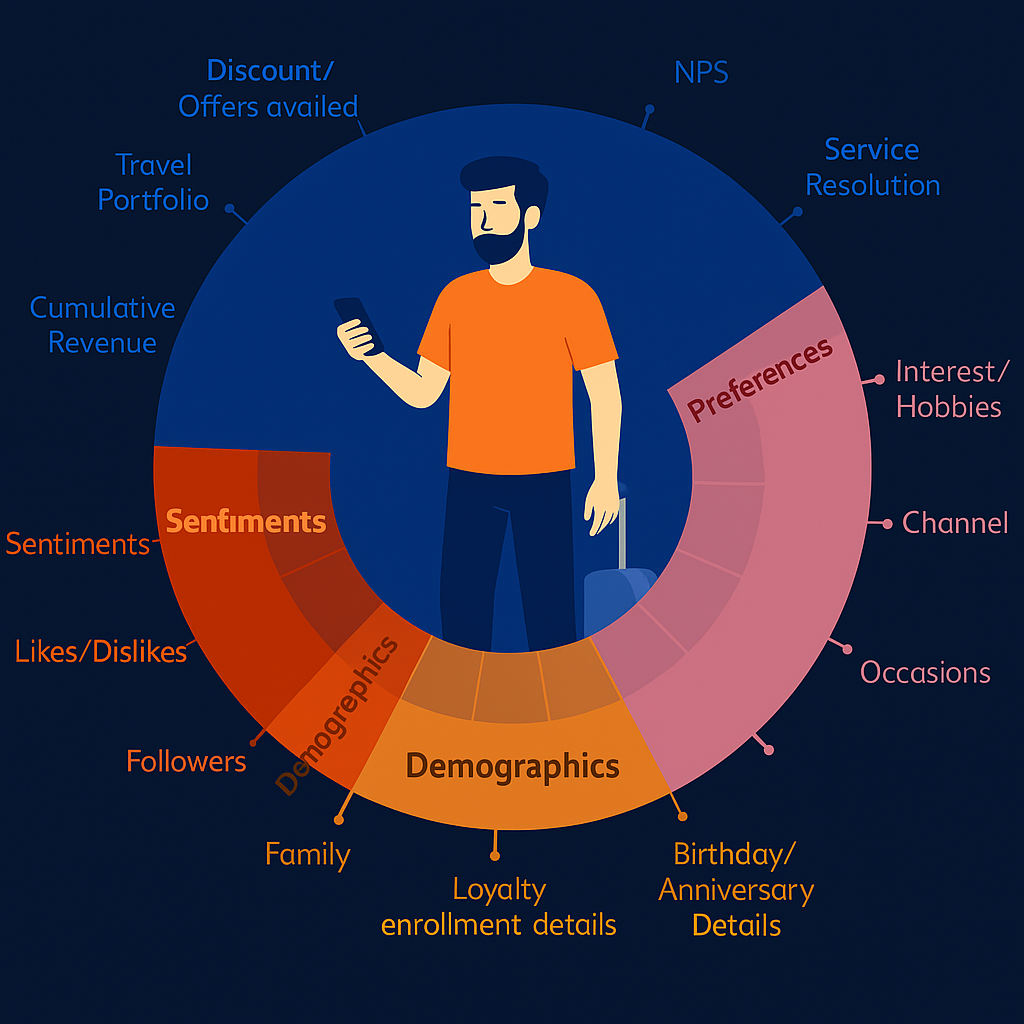
 |
Nếu bạn là một quản lý marketing hoặc điều hành tại công ty du lịch, có lẽ bạn từng trải qua cảm giác "bị lạc giữa rừng dữ liệu": dữ liệu khách hàng có rất nhiều, nhưng rời rạc; các chiến dịch cá nhân hóa thì muốn làm, nhưng lại không đủ công cụ; còn khách hàng thì cứ đến rồi đi, không để lại giá trị lâu dài.
Đó là lý do vì sao CDP (Customer Data Platform) – đặc biệt là nền tảng như LEO CDP – không còn là một "tùy chọn đẹp", mà là một công cụ chiến lược để tăng trưởng bền vững trong ngành du lịch.
Dưới đây là 5 thách thức lớn – cũng là 5 câu hỏi quan trọng – mà bất kỳ quản lý nào trong ngành du lịch hiện đại đều phải đối mặt:
✅ 1. Làm sao để không chỉ bán một lần, mà giữ chân khách hàng sinh lời lâu dài?
Nhiều doanh nghiệp du lịch đang "đuổi theo đơn hàng" – quảng cáo để chốt sale, rồi lại quay về điểm xuất phát. Chi phí cho mỗi khách hàng ngày càng tăng, nhưng họ lại không quay lại.
💡 Giải pháp với LEO CDP:
- Xác định danh tính khách hàng dù họ đến từ đâu (web, mobile, OTA, trực tiếp)
- Dự đoán ai là người có khả năng đặt lại, nâng hạng, hoặc giới thiệu người khác
- Tự động gửi ưu đãi giữ chân khách hàng có giá trị cao (voucher độc quyền, quyền lợi thành viên...)
✅ 2. Làm sao để kết nối trọn vẹn hành trình khách hàng – từ tìm hiểu đến sau chuyến đi?
Một khách hàng có thể tìm kiếm trên Google, xem fanpage, đặt vé qua ứng dụng, rồi gọi tổng đài để hỏi tour. Nhưng nội dung họ nhận được lại không nhất quán – thiếu sự mượt mà trong trải nghiệm.
💡 LEO CDP có thể giúp:
- Theo dõi hành trình của từng khách hàng từ giai đoạn khám phá → đặt dịch vụ → sử dụng → hậu mãi
- Tự động gửi thông điệp đúng thời điểm (ví dụ: gợi ý hành lý sau khi đặt vé, mời đánh giá sau chuyến đi)
- Phân tích điểm rơi trong hành trình – nơi khách có xu hướng bỏ giỏ hàng hoặc không hoàn tất đặt chỗ
✅ 3. Dữ liệu rất nhiều, nhưng làm sao để biến nó thành trải nghiệm thông minh?
Bạn có dữ liệu từ CRM, app, mạng xã hội, email… nhưng không có cách nào để nhìn thấy "bức tranh toàn cảnh" của khách hàng. Trong khi đó, khách thì lại mong muốn trải nghiệm được cá nhân hóa theo sở thích.
💡 Với LEO CDP, bạn có thể:
- Phân khúc tự động dựa trên hành vi: người thích du lịch mạo hiểm, khách gia đình, người đi công tác...
- Phân tích cảm xúc từ bình luận, đánh giá để hiểu rõ mong đợi và cảm nhận thật sự của khách hàng
- Dự đoán giá trị vòng đời để tập trung nguồn lực vào đúng khách hàng mang lại lợi nhuận
✅ 4. Làm sao để nói cùng một ngôn ngữ với khách hàng – dù họ ở kênh nào?
Email gửi một kiểu, app hiện một kiểu, tổng đài tư vấn một kiểu – điều này khiến khách hàng mất niềm tin và làm yếu trải nghiệm tổng thể.
💡 LEO CDP giải bài toán này bằng cách:
- Đồng bộ thông điệp trên các kênh: SMS, WhatsApp, ứng dụng, email, nhân viên chăm sóc
- Cá nhân hóa nội dung dựa trên hồ sơ khách hàng (ví dụ: người nước ngoài sẽ được ưu tiên ngôn ngữ phù hợp, thời gian gửi thông điệp lý tưởng...)
- Cấu trúc dữ liệu khách hàng giúp mọi bộ phận (marketing, CSKH, vận hành) cùng làm việc trên một “bức tranh thật”
✅ 5. Gợi ý sản phẩm – liệu có đang đúng người, đúng lúc?
Bạn có từng thấy hệ thống gợi ý hoạt động kiểu... "cho có"? Gợi ý đại trà, không sát nhu cầu, thậm chí lặp đi lặp lại những gì khách đã mua.
💡 LEO CDP mang lại gợi ý đúng lúc – đúng người – đúng nội dung:
- Dựa trên hành vi duyệt web, vị trí, lịch sử đặt chỗ để cá nhân hóa
- Đề xuất gói linh hoạt: ví dụ “combo vé + khách sạn + trải nghiệm địa phương”
- Sau mỗi chuyến đi, tự động gợi ý chuyến tiếp theo dựa trên sở thích và lịch sử (ex: “Người từng du lịch Huế cũng yêu thích Hà Giang”)
🔍 Kết luận: CDP không còn là một xu hướng – đó là điều kiện để sống sót và tăng trưởng
Trong thời đại mà du lịch không chỉ là dịch vụ, mà là trải nghiệm cá nhân hóa, việc hiểu khách hàng ở cấp độ sâu, hành động theo thời gian thực và tạo ra giá trị trọn đời là điều bắt buộc.
Nếu bạn đang là quản lý tại một công ty du lịch – đây là thời điểm để đặt ra câu hỏi: “Liệu chúng ta đã thực sự biết khách hàng của mình chưa?”
🔗 Hoặc xem demo: https://dcdp.bigdatavietnam.org/


